Jekyll2023-09-24T23:00:39+00:00https://zfhuang99.github.io/feed.xmlCheng Huang’s cornera corner of learning and sharingTLA+ Made Simple with ChatGPT2023-09-24T00:00:00+00:002023-09-24T00:00:00+00:00https://zfhuang99.github.io/tla+/pluscal/chatgpt/2023/09/24/TLA-made-simple-with-chatgpt<h2 id="more-than-just-a-first-impression">More than just a first impression</h2>
<p>Back in 2013, I was working hard on my first implementation of the Paxos consensus protocol. When everything was going smoothly, it worked great. But when I tried some tricky test cases, things often went wrong. It was tough making sure my implementation was perfect, especially with so many possible tests to think of.</p>
<p>I thought to myself, “I can’t be the only one facing this problem.” So, I started looking for better ways to handle these challenges. That’s when I talked to some folks at Microsoft Research and heard about the P programming language [<a href="https://github.com/p-org/P">1</a>]. It felt like I was onto something.</p>
<p>Around the same time, Leslie Lamport was awarded the Turing Award. Not long after the annoucement, Leslie gave a lecture at MSR. The biggest room in building 99 was packed. Everyone wanted to hear from the newest Turing Award winner.</p>
<p>Leslie’s talk had a profound impact on me. I can still remember the title like it was yesterday: “Who Builds a Skyscraper without a Blueprint?”. He was talking about how some of us try to figure out complex distributed systems while we’re writing code, like trying to design a skyscraper while you’re already building it.</p>
<p>That was the first time I heard about TLA+ [<a href="https://lamport.azurewebsites.net/tla/tla.html">2</a>]. Over the next few years, I realized how important TLA+ was for making sure our distributed systems worked right. I became a big fan of TLA+ and even helped to host the first few multi-day TLA+ training sessions by Leslie himself for everyone at Microsoft.</p>
<h2 id="challenges-in-tla-adoption">Challenges in TLA+ adoption</h2>
<p>Despite TLA+ showing promise in real-world systems [<a href="https://lamport.azurewebsites.net/tla/industrial-use.html">3</a>], its widespread adoption remains limited. What seems to be holding it back?</p>
<p>One primary challenge is its relatively steep learning curve. Among the available resources, Leslie’s lectures [<a href="https://lamport.azurewebsites.net/video/videos.html">4</a>] stand out as the most comprehensive guide. To illustrate, one developer from Azure was able to craft detailed specifications after diving into Leslie’s lectures for an entire week. However, for many, this might be an optimistic timeline, with a more realistic learning period often spanning several weeks or even longer.</p>
<p>Another significant concern is the scarcity of resources when facing difficulties. During my time assisting other developers, I observed the struggles they faced in adopting abstract thinking. Without prompt and constructive feedback, refining such skills can be a prolonged journey.</p>
<p>Moreover, the lack of readily available support compounds the issue. When developers grapple with specific aspects of the TLA+ language, finding guidance can often be a challenge in itself.</p>
<h2 id="tla-in-the-age-of-llm">TLA+ in the age of LLM</h2>
<p>The arrival of Large Language Models (LLM) promises a transformative shift, potentially making TLA+ more accessible to a broader range of developers.</p>
<p>Drawing from my recent experiences, I’ve recognized the immense value of using ChatGPT to draft TLA+ specifications and iron out language quirks. A particular moment that struck me was when I realized a flaw in my initial design of a distributed system protocol. After modeling the protocol in TLA+ and running the validation, I was presented with an invariant violation, highlighted by a comprehensive error trace. Out of curiosity, I fed this error trace to ChatGPT. Astonishingly, ChatGPT not only pinpointed the core of the mistake but also offered a list of options to refine the protocol. In this endeavor, ChatGPT emerged as a truly invaluable assistant.</p>
<p>Interestingly, each time I’ve shared this experience with colleagues, they’ve expressed genuine surprise. It seems that the potential synergy between TLA+ and ChatGPT remains largely undiscovered. This realization motivates this article, aiming to enlighten a broader audience.</p>
<h2 id="simplifying-tla-with-chatgpt">Simplifying TLA+ with ChatGPT</h2>
<p>For illustrative purposes, I chose a simple toy consensus protocol to interact with ChatGPT. It’s worth noting that even with more complex and real-world protocol designs, the insights remained consistent. Those curious can find the complete ChatGPT session detailed [<a href="https://chat.openai.com/share/52147e84-ff08-434a-94c8-769701f4d246">5</a>]. Here are some of the key takeaways.</p>
<h3 id="drafting-specification">Drafting specification</h3>
<p>We’ll begin by outlining the distributed system challenge at hand. Then, we’ll prompt ChatGPT to produce a TLA+ specification using PlusCal.</p>
<p align="center">
<img src="/assets/images/tla_draft_spec.jpeg" width="100%" />
</p>
<h3 id="resolving-language-errors">Resolving language errors</h3>
<p>After copying the specification into a .tla file, we employ the TLA+ toolbox for compilation. If the compilation encounters issues, we turn to ChatGPT for error resolution. Interestingly, ChatGPT tends to repeat certain minor errors. Recognizing these patterns allows us to preemptively address them in subsequent prompts by setting a few guiding rules.</p>
<p align="center">
<img src="/assets/images/tla_fix_compile_error.jpeg" width="100%" />
</p>
<h3 id="reviewing-specification">Reviewing specification</h3>
<p>Upon reviewing the specification, I noticed that ChatGPT mistook CHOOSE for representing non-determinism. It’s important to clarify this with the model. Moving forward, incorporating this clarification into our guidelines for future prompts will be beneficial.</p>
<p align="center">
<img src="/assets/images/tla_choose_vs_with.jpeg" width="100%" />
</p>
<h3 id="defining-invariants">Defining invariants</h3>
<p>Having acquired a full TLA+ specification and confirming its correctness through model checking, we can now proceed to establish invariants.</p>
<p align="center">
<img src="/assets/images/tla_define_invariant.jpeg" width="100%" />
</p>
<h3 id="interpreting-error-trace">Interpreting error trace</h3>
<p>When I ran the model checking, it flagged an invariant violation. I turned to ChatGPT to help break down and understand this error trace. I was genuinely taken aback by ChatGPT’s ability to not just delineate the error trace clearly, but also to shed light on the underlying cause of the error.</p>
<p align="center">
<img src="/assets/images/tla_analyze_error_trace_1.jpeg" width="100%" />
<img src="/assets/images/tla_analyze_error_trace_2.jpeg" width="100%" />
</p>
<h3 id="can-chatgpt-mend-distributed-protocols">Can ChatGPT mend distributed protocols?</h3>
<p>It might seem like a tall order, but I decided to challenge ChatGPT: Could it suggest ways to rectify the toy consensus protocol? What stunned me was how ChatGPT didn’t just offer one, but a spectrum of potential solutions, weighing the advantages and drawbacks of each. In the end, I went with the most straightforward solution, and ChatGPT re-generated the specification. The revised spec sailed through the verification process seamlessly. Truly remarkable!</p>
<p align="center">
<img src="/assets/images/tla_mend_protocol.jpeg" width="100%" />
</p>
<h2 id="conclusion">Conclusion</h2>
<p>As AI delivers an unprecedented surge in programming productivity, ensuring the robustness and fail-proof nature of our cloud-scale distributed systems becomes even more paramount. Embracing formal methods like TLA+ and software verification is imperative [<a href="https://zfhuang99.github.io/rust/chatgpt/2023/03/14/implementing-Paxos-in-Rust-with-ChatGPT.html#future-of-ai-assisted-programming">6</a>]. Through this article, I’ve aimed to highlight how ChatGPT can be a game-changer in making TLA+ more approachable. Looking ahead, I envision a future where, with tools like ChatGPT, developers can effortlessly construct more resilient infrastructures at scale.</p>More than just a first impressionPractical Formal Verification for Distributed Systems2023-06-18T00:00:00+00:002023-06-18T00:00:00+00:00https://zfhuang99.github.io/formal%20verification/ivy/2023/06/18/practical-formal-verification<h2 id="introduction">Introduction</h2>
<p>In a rapidly evolving tech landscape where cloud systems scale exponentially and AI-assisted programming takes center stage [<a href="https://zfhuang99.github.io/rust/chatgpt/2023/03/14/implementing-Paxos-in-Rust-with-ChatGPT.html#future-of-ai-assisted-programming">1</a>], mastering the art of balancing outage costs with preventive measures is more critical than ever. This pressing need has invigorated the exploration of formal methods, a domain that includes both model checking, exemplified by tools like TLA+ [<a href="https://lamport.azurewebsites.net/tla/tla.html">2</a>], and formal verification techniques.</p>
<p>While model checking has found its way into practical engineering workflows [<a href="https://lamport.azurewebsites.net/tla/industrial-use.html">3</a>], formal verification remains a largely untapped resource for ensuring the reliability of cloud-scale distributed systems.</p>
<p>In this article, we advocate for a pragmatic approach to formal verification, emphasizing its value as a complement to model checking. Our thesis is straightforward: as AI-assisted programming becomes ubiquitous, the ability to rigorously reason about system correctness will be a key differentiator. Practical formal verification, we argue, could be the missing piece that takes the robustness of cloud-scale distributed systems to the next level.</p>
<h2 id="outage-cost-vs-prevention">Outage: cost vs. prevention</h2>
<!-- {:width="85%"} -->
<p align="center">
<img src="/assets/images/outage_cost_vs_investment_v2.png" width="85%" />
</p>
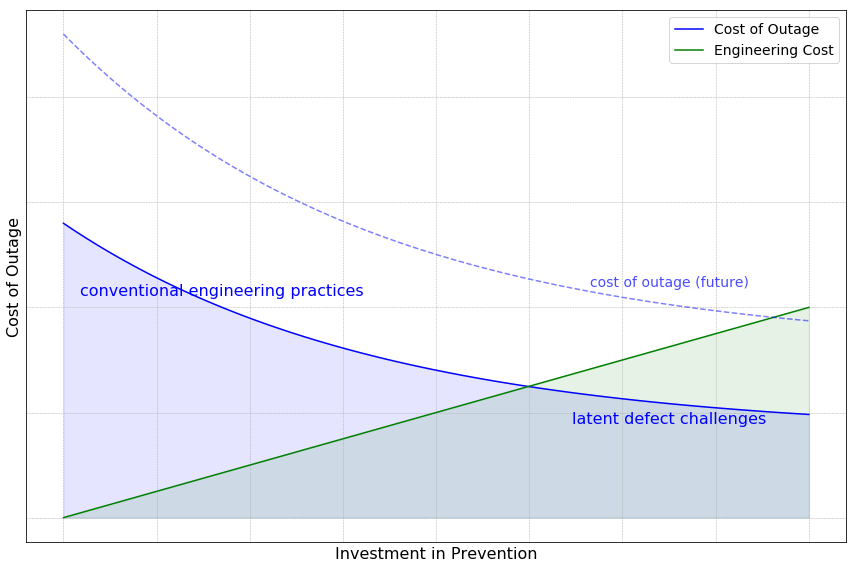
<p>The above graph illustrates the relationship between the cost of outages and the preventive measures taken beforehand. On the x-axis, we have the preventive investments, and on the y-axis, we see the resulting cost when outages cannot be fully prevented.</p>
<p>The blue curve showcases the cost of outages as the product of software defects and their probability. This cost diminishes as preventative investment rises. The upper section of this curve highlights the benefits of conventional engineering practices, such as unit testing, integration testing, and strategic release stages. In this zone, the majority of straightforward software defects are rectified. Moreover, these practices diminish the likelihood of more obscure defects, leading to a steep decline in outage costs with increased investment.</p>
<p>However, as we move towards the bottom section of the curve, the scenario becomes more challenging. Here, latent defects, often deeply embedded in the software stack, remain hidden until significant scaling takes place. These defects, though rare, can have a profound impact. To counter them, a substantial investment is necessary, but the returns (in terms of outage cost reduction) are lesser in comparison to the initial phase. Yet, when weighing the potential damage from these defects against the preventative investment, the decision is clear: it’s prudent to keep investing until an equilibrium is reached.</p>
<p>Compounding this scenario, the blue curve is set to rise with the scaling of cloud systems. Even with a conservative annual growth rate of 20%, the cost of outages will double within four years. In contrast, the green curve, representing engineering costs, increases linearly over time. This discrepancy means that the challenges represented by the bottom section of the blue curve will grow exponentially, making investment in this area increasingly valuable.</p>
<h2 id="landscape-of-formal-methods">Landscape of formal methods</h2>
<!-- {:width="100%"} -->
<p align="center">
<img src="/assets/images/formal_methods.png" width="100%" />
</p>
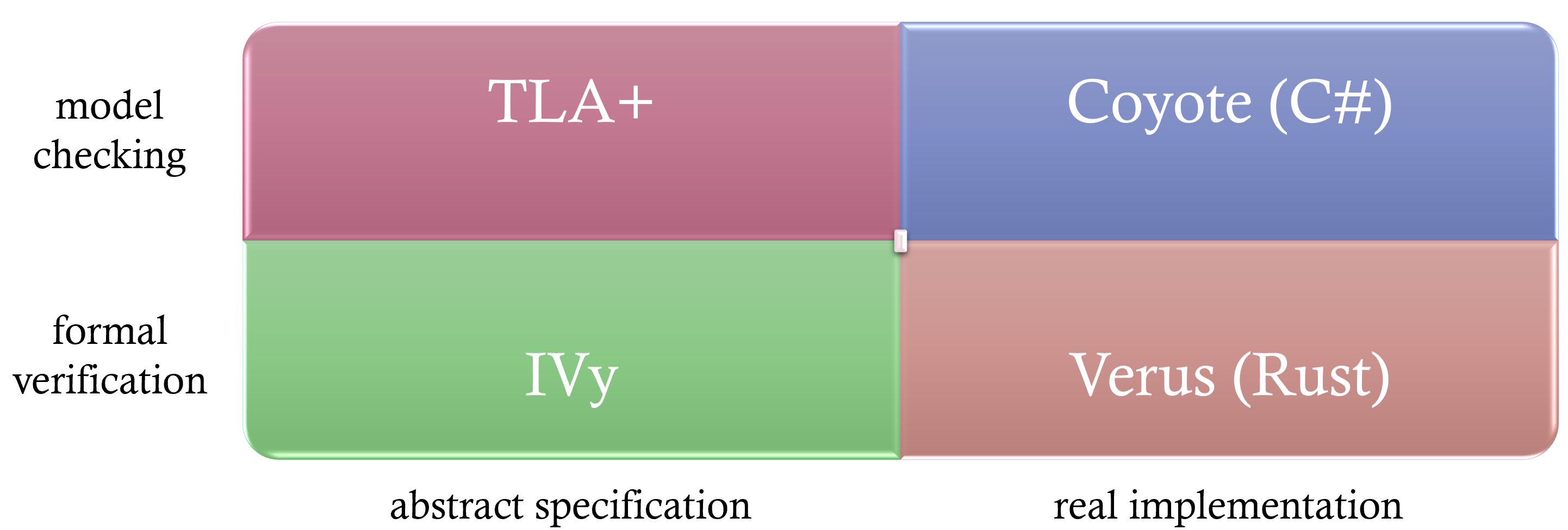
<p>Formal methods can be visualized across four quadrants in a two-dimensional space, categorized by their approach and applicability. The Y-axis differentiates between model checking and formal verification, while the X-axis distinguishes between techniques applied to abstract specifications versus real implementations. Let’s delve into each quadrant:</p>
<ul>
<li>Model checking on real implementation (top-right quadrant):</li>
</ul>
<p>Example: Take Coyote [<a href="https://microsoft.github.io/coyote/">4</a>], originally developed at Microsoft Research and now open-sourced. In traditional testing, executing a test case 100 times yields roughly identical results each time. With Coyote, each execution explores different task interleavings, thanks to its control over asynchronous task scheduling. As a result, invariant violations surface more quickly, and when detected, Coyote captures a trace, allowing for deterministic replay and debugging.</p>
<ul>
<li>Model checking on abstract specification (top-left quadrant):</li>
</ul>
<p>Example: Consider TLA+ [<a href="https://lamport.azurewebsites.net/tla/tla.html">2</a>], a specification language. Real-world systems contain myriad details, many of which are non-essential to verifying correctness. By abstracting core logic and eliminating extraneous details, specifications in TLA+ focus solely on crucial behaviors. Model checking these specifications explores all defined interleavings, capturing and replaying traces whenever an invariant is violated.</p>
<ul>
<li>Formal verification on abstract specification (bottom-feft quadrant):</li>
</ul>
<p>Example: Instead of verifying through exhaustive exploration, formal verification offers mathematical proof of correctness. For instance, using the IVy language [<a href="https://kenmcmil.github.io/ivy/">5</a>], one can abstract essential distributed system logic, write specifications, and then mathematically prove their correctness using the IVy toolchain.</p>
<ul>
<li>Formal verification on real implementation (bottom-right quadrant):</li>
</ul>
<p>Example: Verus [<a href="https://github.com/verus-lang/verus">6</a>] is a pioneering open-source project marrying formal verification with real-world implementation in the Rust language. It exemplifies the potential of integrating rigorous mathematical proofs with tangible, working code.</p>
<h2 id="formal-verification-a-practical-perspective">Formal verification: a practical perspective</h2>
<p>Diving into the realm of formal verification, it’s essential to distinguish between “practical” formal verification and its academic sibling. While both aim for the same overarching goal—ensuring system correctness — their approaches and concerns differ markedly.</p>
<p>From an engineering standpoint, formal verification fills certain voids that model checking doesn’t address. Model checking’s primary challenge lies in the definition of safety properties or invariants. Engineers can usually spell out ultimate safety properties for distributed systems with ease: “ensure no data loss in a storage system” or “a consensus protocol must converge to a single value.” Yet, the intricacies arise due to the global nature of these invariants. To verify them, collaboration among multiple distributed entities becomes indispensable. For instance, confirming no data loss requires consulting all storage nodes, while verifying a consensus protocol demands interrogation of numerous nodes. These global checks are cumbersome in runtime, pushing developers towards local, intermediate invariants that individual nodes can easily enforce. But this approach isn’t without its pitfalls: How many intermediate invariants are enough? Are they comprehensive in ensuring the overarching safety goals?</p>
<p>Enter formal verification. It necessitates the formulation of inductive invariants which, collectively, can vouch for a protocol’s correctness. Interestingly, these inductives often pertain to individual nodes, making their runtime enforcement more feasible.</p>
<p>However, there’s a nuance to appreciate. In practical engineering, the aim of formal verification isn’t just about achieving system correctness. While academics may laud formal verification for its prowess in managing unbounded state spaces, on the ground, this advantage doesn’t always translate to practical superiority. Even bounded model checking often suffices to ensure system correctness. Whether scrutinizing data safety across a set number of nodes or checking a consensus protocol with limited participants, it’s unlikely for a system to work in a restricted setting but fail when scaled. The true value of formal verification lies in its methodical approach — systematically proving correctness, leading us to pinpoint essential inductive invariants. Once identified and transformed into runtime checks, these invariants become the vigilant guardians of system reliability.</p>
<p>To distill our perspective on practical formal verification: It’s about pinpointing the comprehensive set of inductive invariants that vouch for a system’s safety. We’re content with bounded settings, like consensus among a specific number of nodes or ensuring linearizability within a set operation count. By doing so, we often streamline our specifications, even if it means forgoing generalization — a primary concern in academic formal verification.</p>
<h2 id="ivy">IVy</h2>
<p>This is where IVy [<a href="https://kenmcmil.github.io/ivy/">5</a>] comes in. IVy offers both a language for specifying distributed protocols and a toolkit for formal verification. For those who have worked with TLA+, transitioning to IVy is relatively straightforward.</p>
<p>Using IVy is an interactive experience. It starts with specifying a distributed protocol. With a target safety property, you ask IVy to verify it. Since most safety properties aren’t automatically inductive invariants, IVy often rejects the proof and provides counterexamples. These show scenarios where a legitimate state leads to a violation of the safety property after a valid action. This feedback helps users recognize missing base invariants.</p>
<p>The process is iterative: you add these base invariants, and IVy checks them. If IVy still flags issues, its feedback points to the need for more complex inductive invariants. As users propose these invariants, IVy confirms their validity or provides counterexamples. The cycle continues until IVy can’t find any more counterexamples, indicating that the safety property has been proven.</p>
<p>From an engineering viewpoint, this iterative method is useful. Each cycle deepens our understanding of the distributed protocol. Moreover, many of the identified inductive invariants are local, making them easy to implement as runtime checks. By adding these checks to the real system, we transition the correctness assurance from the specification to the actual implementation.</p>
<h3 id="why-not-dafny">Why not Dafny?</h3>
<p>Dafny [<a href="https://dafny.org/dafny/">7</a>] has garnered attention as a tool for the formal verification of distributed protocols. However, based on our experiences, Dafny falls short in serving the specific needs of practical formal verification. A key limitation lies in Dafny’s inability to consistently generate concise and easily understandable counterexamples, a crucial aspect in the journey of identifying inductive invariants.</p>
<h2 id="toy-consensus-example">Toy consensus example</h2>
<p>To grasp the concept of inductive invariants and their discovery, let’s walk through a simplified consensus protocol.</p>
<p><strong>Protocol overview</strong></p>
<ul>
<li>We have three nodes: <code class="language-plaintext highlighter-rouge">n_1</code>, <code class="language-plaintext highlighter-rouge">n_2</code>, and <code class="language-plaintext highlighter-rouge">n_3</code>.</li>
<li>We have two values: <code class="language-plaintext highlighter-rouge">v_1</code> and <code class="language-plaintext highlighter-rouge">v_2</code>.</li>
<li>Nodes can cast a vote for any value, provided they haven’t voted already.</li>
<li>Consensus (or a value being decided) is achieved when 2 out of the 3 nodes vote for the same value.</li>
</ul>
<p><strong>Safety property</strong>
The protocol must ensure that only one value is decided upon. In other words, two different values can’t both achieve consensus.</p>
<p>Take a moment to consider this setup. A node, if it hasn’t previously voted, can vote for any value. Once a value receives votes from two nodes, that value is deemed “decided”. The core safety aspect we’re ensuring is that only one value reaches this “decided” status.</p>
<p><strong>IVy specification</strong></p>
<ul>
<li>Apart from nodes and values, our specification includes two quorums, <code class="language-plaintext highlighter-rouge">q_1</code> and <code class="language-plaintext highlighter-rouge">q_2</code>. The axioms <code class="language-plaintext highlighter-rouge">quorum_q1</code> and <code class="language-plaintext highlighter-rouge">quorum_q2</code> provide the simplest possible definitions for these quorums (e.g., <code class="language-plaintext highlighter-rouge">q_1</code> consists of two nodes <code class="language-plaintext highlighter-rouge">n_1</code> and <code class="language-plaintext highlighter-rouge">n_2</code>), which we’ll elaborate on later.</li>
<li>We employ several relations, which are boolean-returning functions. For those versed in Prolog, these relations should feel familiar. Capitalized variables act as wildcards, matching any instance, whereas lowercase ones pinpoint specific instances. For instance, <code class="language-plaintext highlighter-rouge">vote(N, V)</code> indicates voting status for any node-value pairing, while <code class="language-plaintext highlighter-rouge">vote(n, v)</code> refers to a specific node-value combination.</li>
<li>The initial state, <code class="language-plaintext highlighter-rouge">vote(N, V) := false</code>, signifies that no node has voted. Conversely, the statement <code class="language-plaintext highlighter-rouge">vote(n, v) := true</code> in the <code class="language-plaintext highlighter-rouge">case_vote</code> action indicates a chosen node (denoted as <code class="language-plaintext highlighter-rouge">n</code>) voting for a specific value (<code class="language-plaintext highlighter-rouge">v</code>).</li>
<li>The protocol delineates two actions:
<ol>
<li><code class="language-plaintext highlighter-rouge">case_vote</code>: Here, a node <code class="language-plaintext highlighter-rouge">n</code> can vote if it hasn’t voted before, as represented by the <code class="language-plaintext highlighter-rouge">~vote(n, V)</code> precondition (notice the capitalized V includes all values).</li>
<li><code class="language-plaintext highlighter-rouge">decide</code>: This action is triggered when a quorum of nodes have voted for the same value <code class="language-plaintext highlighter-rouge">v</code>.</li>
</ol>
</li>
</ul>
<pre><code class="language-Ivy">type node = {n1, n2, n3}
type value = {v1, v2}
type quorum = {q1, q2}
relation member(N:node, Q:quorum)
axiom [quorum_q1] member(n1, q1) & member(n2, q1) & ~member(n3, q1)
axiom [quorum_q2] member(n1, q2) & ~member(n2, q2) & member(n3, q2)
relation vote(N:node, V:value)
relation decision(V:value)
action cast_vote(n:node, v:value) = {
require ~vote(n, V);
vote(n, v) := true
}
action decide(q:quorum, v:value) = {
require member(N, q) -> vote(N, v);
decision(v) := true
}
after init {
vote(N, V) := false;
decision(V) := false;
}
export cast_vote
export decide
</code></pre>
<h2 id="interactive-invariant-discovery">Interactive invariant discovery</h2>
<p>Diving into the discovery of inductive invariants, let’s start by stating our primary safety invariant: only a single value can be decided upon. In essence, any two decided values must be identical.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>invariant decision(V1) & decision(V2) -> V1 = V2
</code></pre></div></div>
<p>IVy flags this invariant as non-inductive. The counterexample it provides begins with a state where <code class="language-plaintext highlighter-rouge">decision(v2) = true</code> and <code class="language-plaintext highlighter-rouge">decision(v1) = false</code>, with both <code class="language-plaintext highlighter-rouge">vote(n1, v1)</code> and <code class="language-plaintext highlighter-rouge">vote(n2, v1)</code> being true. This state is valid as it adheres to our invariant. However, executing the <code class="language-plaintext highlighter-rouge">decide</code> action would result in <code class="language-plaintext highlighter-rouge">decision(v1) = true</code>, violating the invariant since both <code class="language-plaintext highlighter-rouge">v1</code> and <code class="language-plaintext highlighter-rouge">v2</code> have now been decided.</p>
<p>This is a pivotal moment in understanding inductive invariants. One might argue that the state of <code class="language-plaintext highlighter-rouge">decision(v2) = true</code> and both votes for <code class="language-plaintext highlighter-rouge">v1</code> isn’t a realistic scenario. This is true, but the essence of inductive invariants lies in the fact that the reachability of the beginning state is irrelevant. As long as it fits the invariant, it’s deemed valid. This counterexample, albeit adversarial, showcases IVy’s robustness.</p>
<p>From this counterexample, it’s clear we must prevent <code class="language-plaintext highlighter-rouge">decision(v2) = true</code> when two nodes have voted for <code class="language-plaintext highlighter-rouge">v1</code>. To fortify our proof, we add an intermediate invariant ensuring that a decided value has the backing of a quorum:</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>invariant decision(V) -> exists Q:quorum. forall N:node. member(N, Q) -> vote(N, V)
</code></pre></div></div>
<p>Yet, IVy rejects the proof again. The new counterexample retains the original state but adds both <code class="language-plaintext highlighter-rouge">vote(n1, v2) = true</code> and <code class="language-plaintext highlighter-rouge">vote(n2, v2) = true</code> because of the added invariant.</p>
<p>It’s evident that having both <code class="language-plaintext highlighter-rouge">vote(n1, v1)</code> and <code class="language-plaintext highlighter-rouge">vote(n1, v2)</code> as true is problematic, indicating a node has voted twice. So, we introduce another invariant, which states all the values voted by an arbitrary node must be be identical.</p>
<div class="language-plaintext highlighter-rouge"><div class="highlight"><pre class="highlight"><code>invariant vote(N, V1) & vote(N, V2) -> V1 = V2
</code></pre></div></div>
<p>With this addition, IVy accepts the invariants, collectively making them inductive. This confirms the safety of our target invariant under the given specification — no two values can simultaneously be decided. Crucially, the final invariant is local, pivotal for correctness, and can be continuously validated during runtime. We can envision each node maintaining a tally of its votes, with any node exceeding one vote indicating a potential breach of the invariant. This methodology extends to more intricate protocols, like Paxos, where individual nodes can also monitor local conditions to ensure system safety.</p>
<h2 id="simplification-via-specificity">Simplification via specificity</h2>
<p>One of the key hallmarks of “practical” formal verification lies in the art of simplification. Let’s delve into how this is highlighted in our toy concensus specification.</p>
<p>Firstly, we limit the scope to just 3 nodes and 2 values. This might seem restrictive, but it aligns perfectly with our primary objective: the discovery of all inductive invariants. Smaller specifications not only speed up the verification process but also yield counterexamples that are easier to interpret.</p>
<p>Secondly, we use specific axioms to define our quorums. Instead of adopting a generic representation that demands overlapping nodes between any two quorums, we go for a more straightforward approach. This simplification doesn’t compromise our ability to identify all the required inductive invariants.</p>
<p>However, it’s worth noting that these simplifications come with their trade-offs. For example, if we decide to extend the system to handle more nodes and values, we’ll need to manually update the specification. This is generally a one-time effort to avoid unexpected surprises.</p>
<p>Also, keep in mind that extending the specification can significantly increase the time required for verification. For instance, in a specification modeling the Paxos concensus protocol, when expanding the sets of Ballot IDs and values, the verification time shot up exponentially. To illustrate, allowing ballots to choose between 0 and 7, and values from a set of 3, took nearly 3 hours for verification. While it’s possible to craft a more complex specification that verifies faster, it contradicts our aim in practical formal verification: simplicity is key, as long as it enables us to identify all inductive invariants.</p>
<table>
<thead>
<tr>
<th>Ballot ID</th>
<th>Value</th>
<th>Verification Time</th>
</tr>
</thead>
<tbody>
<tr>
<td>0, 1, 2, 3</td>
<td>{v1, v2}</td>
<td>4.5s</td>
</tr>
<tr>
<td>0, 1, 2, 3</td>
<td>{v1, v2, v3}</td>
<td>5.9s</td>
</tr>
<tr>
<td>0, 1, …, 7</td>
<td>{v1, v2}</td>
<td>6m27s</td>
</tr>
<tr>
<td>0, 1, …, 7</td>
<td>{v1, v2, v3}</td>
<td>171m26s</td>
</tr>
</tbody>
</table>
<h2 id="conclusion">Conclusion</h2>
<p>In an imminent future, where AI-assisted programming takes center stage [<a href="https://zfhuang99.github.io/rust/chatgpt/2023/03/14/implementing-Paxos-in-Rust-with-ChatGPT.html#future-of-ai-assisted-programming">1</a>], the capability to reason and ascertain high-level system correctness will stand out as a pivotal differentiating skill. For those of us crafting the foundational layers of cloud-scale distributed infrastructure, it’s imperative to not only familiarize ourselves with tools like TLA+ but to also become adept at practical formal verification. It isn’t just about knowing the tools — it’s about seamlessly integrating them into our everyday workflow, ensuring that the systems we build are robust and fail-proof.</p>IntroductionImplementing Paxos in Rust with ChatGPT2023-03-14T00:00:00+00:002023-03-14T00:00:00+00:00https://zfhuang99.github.io/rust/chatgpt/2023/03/14/implementing-Paxos-in-Rust-with-ChatGPT<h2 id="introduction">Introduction</h2>
<p>This article provides an overview of my experience implementing Paxos in Rust, aided by the advanced language model, ChatGPT. This journey, which involved a thorough ChatGPT session spanning multiple days, covered an extensive range of topics. These stretched from mastering fundamental language constructs to troubleshooting compiler errors and exploring advanced areas such as concurrency, asynchronous programming, and model checking.</p>
<p>The dynamism of this interaction led to a noticeable surge in my productivity, enabling me to complete a substantial amount of work in a rather condensed timeframe. Impressively, the entire project was wrapped up in less than a week, with roughly 2-3 hours invested on weekdays and an additional half-day over the weekend.</p>
<p>I would be remiss not to mention that this was my <em>inaugural</em> Rust project. Despite having a basic grasp of the language from prior resources like “Rust by Example” and the completion of “rustlings” — a compilation of 94 mini assignments designed to introduce Rust concepts — this project truly underscored the remarkable capabilities of ChatGPT in alleviating Rust’s infamously steep learning curve.</p>
<p>The experience left me profoundly convinced of the transformative potential that the synergy of Rust and ChatGPT holds for the field of <em>infrastructure software development</em>. Rust’s unique ability to deliver code devoid of memory leaks, crashes, and race conditions ensures a robust and efficient software infrastructure. Coupling this with the problem-solving prowess of ChatGPT can help us navigate the more intimidating facets of Rust, including its compiler errors and learning curve.</p>
<p>Moreover, this expedition offered an insight into the probable future of AI-assisted programming. With the support of AI, developers’ productivity could reach new heights, enabling the generation of significantly larger volumes of code. However, it’s essential to bear in mind that AI-generated code is not inherently bug-free. To ensure the robustness of our software infrastructure in the face of an influx of new code, a proactive approach is needed. Rust, with its prowess in minimizing low-level bugs, is a formidable tool for this task. To navigate the realm of high-level bugs, we must rely on formal methods like TLA+ and other formal verification techniques.</p>
<h3 id="why-paxos">Why Paxos</h3>
<p>Paxos is one of the most fundamental protocols anchoring many distributed systems. A simple implementation of Paxos might involve two proposers each trying to commit their own value among three acceptors. This process involves concurrency, as the requests from the proposers may compete with each other at any of the acceptors in an arbitrary sequence. Furthermore, the process involves asynchrony. When a proposer sends requests to the acceptors, the responses might return in any order or not at all, in the event of network issues. Implementing Paxos provides an opportunity to thoroughly comprehend both the concurrency and asynchrony aspects of Rust, making it an appealing choice for my inaugural project.</p>
<h2 id="highlights-of-chatgpt">Highlights of ChatGPT</h2>
<p>The comprehensive ChatGPT session, including numerous interactions around compiler errors, is accessible [<a href="https://chat.openai.com/share/263d8cb4-0001-46de-bbea-d2a07de60f9c">1</a>] for those interested. To offer a snapshot of the expansive spectrum of assistance provided by ChatGPT, I’ve compiled a few standout moments below.</p>
<h3 id="getting-started">Getting started</h3>
<p>Here is the initial prompt! Although ChatGPT’s comprehensive knowledge of Paxos is impressive, what amazed me even more was its ability to infer that I intended to develop Paxos on a key-value store, deduced merely from the project name.</p>
<p>This also implies that, to maximize the potential of Large Language Models like ChatGPT, we should try to translate the problems we’re tackling into concepts that are familiar and easily understood.</p>
<!-- {:width="90%"} -->
<p><img src="/assets/images/rkvpaxos_getting_started_dark.jpg" alt="getting_started" width="90%" /></p>
<h3 id="define-data-structure">Define data structure</h3>
<p>Here are a few examples of me asking ChatGPT to define some basic data structures and tailoring the definitions based on my need.</p>
<p><img src="/assets/images/rkvpaxos_define_data_structure_dark.jpeg" alt="define_data_structure" width="90%" /></p>
<h3 id="program-async">Program async</h3>
<p><img src="/assets/images/rkvpaxos_write_async_method_dark.jpeg" alt="write_async_method" width="90%" /></p>
<h3 id="create-unit-tests">Create unit tests</h3>
<p><img src="/assets/images/rkvpaxos_create_unit_test_for_given_method_dark.jpeg" alt="create_unit_test_for_given_method" width="90%" /></p>
<h3 id="rewrite-as-rust-native">Rewrite as Rust native</h3>
<p><img src="/assets/images/rkvpaxos_pattern_matching_dark.jpeg" alt="pattern_matching" width="90%" /></p>
<h3 id="revamp-implementation">Revamp implementation</h3>
<p>My interaction with ChatGPT led me to realize that ‘channels’ might be a powerful primitive for implementing Paxos. Specifically, consider a scenario where a proposer sends a voting request to three acceptors. As soon as it receives responses from at least two of the three, it can conclude a voting round. This can be implemented elegantly using channels — the proposer simply listens on a channel, with each individual response from different acceptors delivered via the same channel. This way, the proposer can implement a straightforward loop and tally the responses, sidestepping the need for complex concurrency primitives. With this insight, I requested ChatGPT to revamp the implementation.</p>
<p>Given that most of my time was spent prompting and editing, this request for a significant rewrite didn’t feel particularly taxing.</p>
<p><img src="/assets/images/rkvpaxos_entire_method_with_updated_design_dark.jpeg" alt="entire_method_with_updated_design" width="90%" /></p>
<h3 id="refactor">Refactor</h3>
<p>By this stage, I had successfully implemented Paxos Phase 1 and Phase 2. Adhering to the principle of prioritizing functionality before optimization, there was some degree of redundancy between the two phase implementations. To my delight, I realized I could simply request ChatGPT to refactor the duplicated code on my behalf.</p>
<p><img src="/assets/images/rkvpaxos_refactor_duplicated_code_dark.jpeg" alt="refactor_duplicated_code" width="90%" /></p>
<h3 id="model-checking">Model checking</h3>
<p>When AWS unveiled their ShardStore paper [<a href="https://www.amazon.science/publications/using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3">2</a>] at SOSP, the authors open-sourced a model checking framework for Rust, named Shuttle. Having never explored Shuttle before and having little interest in poring over its documentation, I decided to task ChatGPT with explaining its workings. With just a few prompts, I quickly grasped the essence of the framework and understood how I could potentially incorporate it into my own testing regime — a task for another day.</p>
<p><img src="/assets/images/rkvpaxos_model_checking_dark.jpeg" alt="model_checking" width="90%" /></p>
<h2 id="future-of-ai-assisted-programming">Future of AI-assisted programming</h2>
<p>This journey has deeply convinced me of the imminent rise of Rust as a dominating force in infrastructure software development, potentially surpassing C++.</p>
<p>As more developers begin to embrace AI assistance, a tremendous increase in productivity is predicted, facilitating the generation of much larger volumes of code. However, it’s crucial to note that AI-generated code isn’t exempt from bugs. A recent study [<a href="https://arxiv.org/abs/2211.03622">3</a>] revealed that “participants who had access to an AI assistant wrote significantly less secure code” and “were more likely to believe they wrote secure code.” While this study centered around security, it’s reasonable to infer that its conclusions could be applicable to other areas such as availability and reliability.</p>
<p>In the wake of this anticipated surge in productivity, the need to maintain high reliability within our infrastructure software stack is of utmost importance. The escalating demand for stability is likely to elevate Rust as the most desirable choice. This is largely due to Rust’s proficiency in mitigating low-level bugs such as memory leaks, crashes, and race conditions.</p>
<p>However, Rust alone can’t guarantee high-level correctness, such as ensuring safety (preventing data loss in storage systems) or liveness (always enabling users to upload and read blobs). Until LLMs evolve to develop profound reasoning capabilities, these aspects will remain as significant areas of expertise for developers. To address high-level bugs, formal methods, such as TLA+ and formal verification, are increasingly being adopted as effective strategies.</p>
<p>As AI-assisted programming becomes the norm, every developer’s AI co-pilot will become standardized, making them largely interchangeable. Therefore, the ability to tackle high-level correctness issues effectively will emerge as a key differentiator. This skill will be instrumental in maintaining the relevance of human developers in the rapidly evolving landscape of infrastructure software development.</p>Introduction